Introduction
Previously, I showed how one could write a function to convert a subset of markdown into HTML in all of its gory detail.[1] While this was enlightening, and I'm relatively proud of it, there is a better way. Three difficulties I found were: updating the grammar when I noticed something was missing was increasingly difficult, and accounting for recursive rules was difficult with a character–by–character approach.
ANTLR by Terence Parr removes both of these issues.[2] Here, one can write out a grammar in a small file or two, generate some files, and then write a couple of Java (or JavaScript, or Python) files to implement the logic around them.
Below I outline the grammar I used for the subset of markdown I am interested in, implement a Java class to generate the necessary HTML tags, and subject it to the tests from the previous outing.
Tomassetti's The ANTLR Mega Tutorial is an excellent starting point for those wanting to get their feet wet, and I used it to learn how to write use ANTLR.[3] Parr has a small markdown grammar listed on GitHub.[4] I read this after I ran into a roadblock with the first grammar I wrote, and subsequently took inspiration to put more into the parser than the lexer. IntelliJ has a supremely useful plugin for ANTLR, which allows one to visualised the parse tree of some input with the current grammar.[5]

Using the ANTLR plugin in IntelliJ
myMDToHTML.g4
Lexer Rules
All ANTLR grammar files are stored as
g4
files. Each grammar is composed of a parser and a lexer. These can be stored in the same file, or split across two different files.
A lexer takes some text and breaks into into 'tokens'.[6] In the lexer, one defines what the building blocks of the incoming language are. For the subset of markdown I'm interested in, these are words, numbers, whitespace, and numbers. Some of these are themselves made up of smaller pieces. Words are made of uppercase and lowercase characters, and numbers are made up of digits. In ANTLR, these smaller pieces are 'fragments', which are used to build larger lexical tokens.
A parser takes these lexical tokens and uses them to figure out what structure they are in.[7] For instance, here we need to determine if some tokens represent a heading, an unordered list, a table, a code block, and so forth.
Let's start with the lexical rules. These are placed after the parser rules in the
.g4
file. Some parts are quoted from Tomasetti's example.[8]
grammar myMDToHTML;
//...
/*
* Lexer Rules
*/
NUMBER : [0–9]+ ;
WORD : ([a–zA–Z] | '_')+ ;
WHITESPACE : (' ' | '\t') ;
NEWLINE : ('\r'? '\n' | '\r') ;
WORDNUMBERWHITESPACE : WORD
| NUMBER
| WHITESPACE
;
Looks fairly harmless. The
(A | B)
allows one to say that this position could be filled by either
A
or
B
. The
+
at the end means
at least one of
, allowing for repeated characters.
WORDNUMBERWHITESPACE
can refer to any of the three, with
|
providing
OR
logic.
?
means
zero or one occurrances of
. As Windows machines use
\r
before
\n
the
?
allows us to account for the possibility that there is a return carriage rather than simply a new line character.
The
[0–9]
and
[a–zA–Z]
could be extracted out into fragments should new lexical elements be introduced which need them. In some grammars the whitespace characters are skipped entirely (e.g.
' ' –> skip ;
). I've kept them in here, as I found skipping them led to sentences mashed together into some incomprehensible mess.
Parser Rules
The parser rules are more interesting. This is more involved, and I'll present it step–by–step.
The rules generally go from more general to more specific. At the most general, I have a markdown file. This is some collection of elements followed by an
EOF
token.
grammar myMDToHTML;
/*
* Parser Rules
*/
mdfile : sentence+ EOF ;
Below that I have created a
sentence
. This contains at least one instance of some smaller element, followed by at least one new line character. Admittedly,
sentence
is not the best name for this element, as some of the items below are tables and lists. However, it captures the basic structure in mind and therefore I've left it as–is for now.
sentence : markdownItem+ NEWLINE+ ;
These markdown items allow the program to determine what the major parts of the file are. In the case that the current tokens do not adhere to any of these rules, I've said that
default
should appear one or more times. This is for paragraphs of text without any special formatting.
markdownItem : header
| codeBlock
| italicsAndBold
| bold
| italics
| footnote
| table
| image
| list
| link
| exclamationMark
| default+
;
Headers are quite simple. One or more instances of a
#
followed by some plain text or symbols.
header : '#'+ (pound | exclamationMark | default)+ ;
There are a number of tokens which may be intended as plain text within a header, code block, or some other element, but are also used to identify a rule. For example,
#
is used to identify the start of a header, but one may also want the ability to use the pound symbol as a plain character within a header. Having
#
it in either the
default
rule or as a lexical token instead causes ANTLR to think that a different rule has started, preventing the entire header from being parsed correctly. This is the same reason why we haven't seen
default
yet – it needs to be later on in the parser rules so that ANTLR first considered the more complicated rules and then checks for the
default
. Therefore, I defined separate parser rules. These occur only after all the rules which rely on these symbols, so avoid any confusion.
So, why not simply declare something such as
('#' | default)+
? With this approach, ANTLR will correctly identify the rule to apply, but then it is trickier to add the
#
into the final output text. As a separate rule, however, ANTLR will produce a new method, where one can add the
#
to the output string as needed.
codeBlock : '```' WORD NEWLINE codeBlockLine+ '```' # multilineCodeBlock
| ('``' | '`' (default | verticalLine | pound | asterisk)+ '`') # inlineCodeBlock
//...
codeBlockLine : (default | verticalLine | asterisk | pound | exclamationMark | backquote)* NEWLINE ;
pound : '#' ;
verticalLine : '|' ;
asterisk : '*' ;
dash : '–' ;
backquote : '`' ;
carat : '^' ;
exclamationMark : '!' ;
Code blocks are relatively straightforward. The multi–line code blocks are considered first so that ANTLR checks for them before looking for inline code blocks. The
# names
comments are used to produce separate methods for the multiline and inline code blocks.
Note that there is no proper recursion with code blocks here. A multi–line code block may contain since backquotes, enabled by the
backquote
rule, but the current grammar does not allow it to contain another new multi–line code block within it.
Obsidian automatically adds some syntax highlighting if a programming name (e.g.
Java
) is included immediately after the backquotes. This is helpful for editing and can be used to identify the multi–line code blocks. After this word is a
NEWLINE
character, before the contents of the code block itself.
The
codeBlockLine
rule is placed near the bottom of the parser rule set, to avoid it being mistaken for other rules. Whilst using the ANTLR plugin, I found it easier to have the different lines within a multiline code block separated into their own tree branches. Both the
|
and
*
characters are used for other rules, and caused a number of parsing issues when kept as either lexical tokens or in
default
. I also wanted to replace them with their HTML entity versions. Therefore, they have their own parser rules, which are referred to by the
codeBlockLine
. These are at the bottom of the parser rule set, to avoid confusing ANTLR.
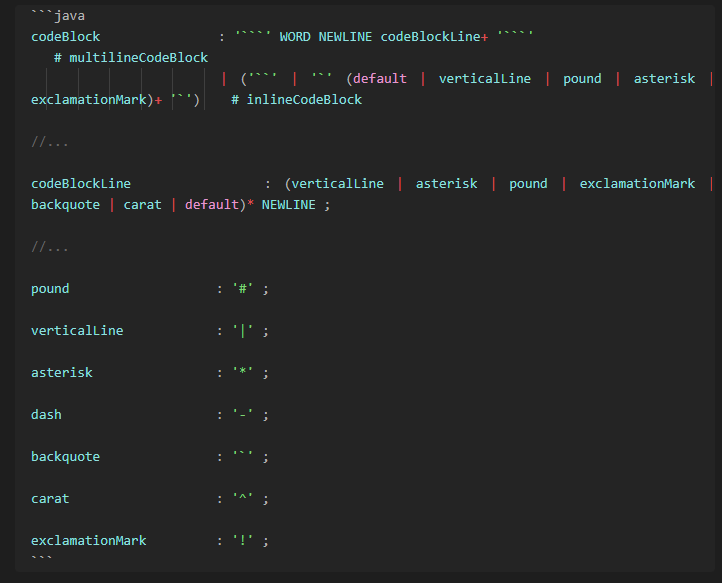
An example of a multi–line code block in Obsidian.
italicsAndBold : '*' '*' '*' boldItalicsInterior+ '*' '*' '*' ;
bold : '*' '*' boldItalicsInterior+ '*' '*' ;
italics : '*' boldItalicsInterior+ '*' ;
//...
boldItalicsInterior : default
| pound
| verticalLine
| dash
| carat
| exclamationMark
;
Here, I've only considered italics and bold characters indicated with
*
rather than with
_
. This assumption is only possible due to me having control over the input.
As noted earlier, to avoid bold text being mistaken for italics text, the bold rule comes first and has to be discarded by ANTLR before the italics rule is considered. Dashes are added as separate parser rules, so that they do not result in a mix–up between unordered lists and plain dashes.
There are a number of characters which can appear with emboldened and italicised text. For convenience, these have been collected under a separate parser rule.
footnote : '[' '^' NUMBER ']' ':' footnoteSentence # endOfFileFootnote
| '[' '^' NUMBER ']' # inlineFootnote
;
//...
footnoteSentence : (italicsAndBold | bold | italics | pound | exclamationMark | dash | default)+ NEWLINE* ;
There are two types of footnotes in these posts. The one at the end of the file contains a few more elements, and is thus placed first in the rule order.
The sentences included in the footnotes at the end may have bold or italics text in addition to plain text, for example if a journal article name is quoted.
pound
is also referenced, for instances where a URL includes a
#
in it.
image : '!' '[' '[' imageName ']' ']' ;
//...
imageName : (WORD | NUMBER | WHITESPACE | '_')+ '.' WORD+ ;
An
image
is also identified by a very specific structure. No other structures start with
!
so there are no conflicts with other rules.
Each image name has a distinct structure, where the file name can (but does not need to) contain a
_
, and has a
.
before the file type.
The
imageName
rule is placed very late in the parser rules, to avoid confusing ANTLR.
list : ('–' listLine)+ ;
listLine : (codeBlock | italicsAndBold | bold | italics | footnote | link | exclamationMark | default)+ NEWLINE ;
Lists are defined by a series of
–
followed by some text or markdown elements. Note that the
NEWLINE
characters are included in the list lines and not
list
itself. The
list
will have an additional
NEWLINE
character after it due to the
sentence
rule.
table : tableHeader tableBorder tableBodyRow+ ;
tableHeader : '|' (tableHeaderCell+ '|')+ NEWLINE ;
tableBorder : '|' ('–'+ '|')+ NEWLINE ;
tableBodyRow : '|' (tableCell '|')+ NEWLINE? ;
tableHeaderCell : default+ ;
tableCell : default+ ;
The relatively large number of rules for a table belies its simplicity. In Obsidian's markdown a table has three sections: the head, a border line, and the body itself. Each of these simply contains some
|
with text between them. As we don't know how wide the table is, we simply state that there is at least one row. If there isn't, the table is malformed.
The header cells and table cells are declared as separate parser rules so that they have different methods, one to add
<th>
tags, and another to add
<td>
tags.
link : linkStart linkEnd ;
linkStart : '[' default+ ']' ;
linkEnd : '(' default+ ')' ;
Links have been split into a couple of different rules. Markdown and HTML have the text and URLs for links in the opposite order to each other. The split here is to help with catching the text to go between the anchor tags and then append it after the URl has been added.
default : WORD
| NUMBER
| WHITESPACE
| ':'
| '–'
| '"'
| '\''
| '<'
| '>'
| '('
| ')'
| '{'
| '}'
| '['
| ']'
| ','
| '.'
| '_'
| ';'
| '/'
| '?'
| '='
| '@'
| '‘'
| '’'
| '+'
| '\\'
| '&'
| '%'
;
footnoteSentence : (italicsAndBold | bold | italics | pound | default)+ NEWLINE* ;
imageName : (WORD | '_')+ '.' WORD+ ;
codeBlockLine : (default | verticalLine | asterisk)* NEWLINE ;
pound : '#' ;
verticalLine : '|' ;
asterisk : '*' ;
// lexical rules
At last,
default
. This simply contains
WORD
s,
NUMBER
s,
WHITESPACE
lexical tokens, or a number of other characters I want to identify. These do not need to be declared as their own parser rules as they do not cause issues with later parser rules, and the
default
- related method produced by ANTLR will allow me to record of substitute them for HTML entities at will.
The Java Directory Structure
A simple directory structure for this project is:
– antlr_md_to_html
| – .idea
| – grammar
| – myMDToHTML.g4
| – lib
| – antlr–4.13.1–complete.jar
| – ...
| – mdToTranspile
| – blog_post.txt
| – src
| – AntlrParser
| – AntlrParserTest
| – HtmlMdListener
| – HtmlMdListenerTest
| – Main
| – myMDToHTML.interp
| – myMDToHTML.tokens
| – myMDToHTMLBaseListener
| – myMDToHTMLLexer
| – myMDToHTMLLexer.interp
| – myMDToHTMLLexer.tokens
| – myMDToHTMLListener
| – myMDToHTMLParser
| – .gitignore
| – antlr4.bat
| – antlr_md_to_html.iml
| – grun.bat
The
myMDToHTML
comes from the ANTLR website.[9]
It is a jar which can be run from the command line.
I developed this on a Windows machine. A pair for
.bat
files simply contain the scripts needed to run the ANTLR jar.[10]
antlr4.bat:
java –cp "path_to_jar\antlr–4.13.1–complete.jar" org.antlr.v4.Tool %*
grun.bat:
java –cp "path_to_jar\antlr–4.13.1–complete.jar" org.antlr.v4.gui.TestRig %*
Note that when ANTLR is run from powershell (e.g.
.\antlr4.bat .\grammar\myMDToHTML.g4
), it will produce all of the files of interest in the
grammar
directory. I moved these over to
src
later on.
Main
The main file is straightforward. It simply reads in a file, sends its contents to a the transpiler, and saves the output to an HTML file.
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.stream.*;
public class Main {
public static void main(String[] args) {
try {
// Read in the text file:
//https://www.baeldung.com/reading–file–in–java
Path pathToFile = Paths.get(args[0]);
String pathToImageDirectory = args[1];
Stream<String> lines = Files.lines(pathToFile);
String mdTextToTranspile = lines.collect(Collectors.joining("\n"));
lines.close();
// Save the output to an html file:
//https://www.baeldung.com/java–write–to–file
BufferedWriter writer = new BufferedWriter(new FileWriter("html_out.html"));
writer.write(AntlrParser.transpileMDToHTML(mdTextToTranspile, pathToImageDirectory));
writer.close();
} catch (java.io.IOException e) {
System.out.println("IOException");
System.out.println(e.getMessage());
}
}
}
ANTLRParser
ANTLRParser
uses the standard layout for an ANTLR project. The incoming string is turned into a character stream, which fed into the lexer, which is then turned into a common token stream, before being read by the parser. Afterwards, we instantiate a parser tree and a listener, walk through it, and return the result.
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
import java.io.IOException;
public class AntlrParser {
public static String transpileMDToHTML(String mdToTranspile, String pathToImage) {
if (mdToTranspile.isEmpty()) {
return "";
}
CharStream charStream = CharStreams.fromString(mdToTranspile);
myMDToHTMLLexer mdToHTMLLexer = new myMDToHTMLLexer(charStream);
CommonTokenStream commonTokenStream = new CommonTokenStream(mdToHTMLLexer);
myMDToHTMLParser myMDToHTMLParser = new myMDToHTMLParser(commonTokenStream);
myMDToHTMLParser.setBuildParseTree(true);
myMDToHTMLParser.MdfileContext tree = myMDToHTMLParser.mdfile();
HtmlMdListener htmlMD = new HtmlMdListener(pathToImage);
ParseTreeWalker.DEFAULT.walk(htmlMD, tree);
return htmlMD.getOutString();
}
}
HtmlMdListener
With the default settings ANTLR will produce a
Listener
based on the grammar provided to it. In Java this will be an interface such as the following:
public interface myMDToHTMLListener extends ParseTreeListener {...}
This then needs to be implemented by a separate Java class, which in this case will add all of the html tags.
Initialising
Some helper variables are created when initialising, for instance to help with adding HTML entities, keep track of the current inline footnote number, and update the path to the image directory to include in the HTML file.[11] A few of these are used to rearrange footnotes at the end of the file.
The other basic method included here is to return the string value from the
StringBuilder
.
import org.antlr.v4.runtime.ParserRuleContext;
import org.antlr.v4.runtime.tree.ErrorNode;
import org.antlr.v4.runtime.tree.TerminalNode;
import java.util.Objects;
import java.util.HashMap;
public class HtmlMdListener implements myMDToHTMLListener {
private final StringBuilder OutString = new StringBuilder();
private String imagePath = "/directory_name/";
private final HashMap<String, String> htmlEntityMap = new HashMap<String, String>();
private int currentInlineFootnoteNumber = 1;
private final HashMap<Integer, Integer> footnoteMap = new HashMap<Integer, Integer>();
private boolean addingTextBetweenAnchorBrackets = false;
private final StringBuilder textBetweenAnchorBrackets = new StringBuilder();
private boolean addingEndNotes = false;
private final StringBuilder currentEndNoteString = new StringBuilder();
private final HashMap<Integer, String> endNotes = new HashMap<Integer, String>();
private int currentHeaderCount = 0;
public HtmlMdListener(String pathToImageDirectory) {
this.htmlEntityMap.put("\"", """);
this.htmlEntityMap.put("&", "&");
this.htmlEntityMap.put("<", "<");
this.htmlEntityMap.put(">", ">");
this.htmlEntityMap.put("–", "–");
this.htmlEntityMap.put("'", "'");
this.htmlEntityMap.put("|", "|");
if (!Objects.equals(pathToImageDirectory, "")) {
this.imagePath = pathToImageDirectory;
}
}
public String getOutString() {
return this.OutString.toString();
}
//...
}
Everything beyond this are pairs of
enter
and
exit
methods for the different parser rules.
In nearly all cases, the
enter
method adds an opening HTML tag, whilst the
exit
method adds a closing HTML tag. The logic for adding different words, numbers, and so forth is devolved to their relevant methods, unlike the functions I wrote in the previous post.
Entering and Exiting the MD File
@Override
public void enterMdfile(myMDToHTMLParser.MdfileContext ctx) {
this.OutString.append("<html>\n<head>\n<meta charset=\"UTF–8\"/>\n</head>\n<body>\n<div class=\"content\">\n");
}
@Override
public void exitMdfile(myMDToHTMLParser.MdfileContext ctx) {
if (addingEndNotes) {
for (int i = 1; i < currentInlineFootnoteNumber; i++) {
this.OutString
.append("<p id=\"footnote–")
.append(i)
.append("\">\n")
.append("<a href=\"#footnote–anchor–")
.append(i)
.append("\">\n")
.append("[")
.append(i)
.append("]\n</a>\n");
this.OutString.append(endNotes.get(i));
this.OutString.append("</p>\n");
}
this.OutString.append("</p>\n");
}
this.OutString.append("</div>\n</body>\n</html>");
}
Upon entering, the HTML tags needed to create the basic structure of an HTML file are appended to the
StringBuilder
. New line characters are included solely to make the out file more readable. Upon exiting, if there are end notes to add, they are all added in one go.
This reordering of the end notes is the primary factor leading to increased complexity in this code, and will come back in multiple places later on.
Sentences
@Override
public void enterSentence(myMDToHTMLParser.SentenceContext ctx) {
this.OutString.append("<p>\n");
}
@Override
public void exitSentence(myMDToHTMLParser.SentenceContext ctx) {
if (!addingEndNotes) {
this.OutString.append("\n</p>\n");
}
}
Entering and exiting sentence nodes is relatively simple. The closing
</p>
is not added if there are still end notes to add.
Markdown Items
No tags are added for entering an exiting markdown items. At this level, it isn't possible to identify which HTML tags would have to be added here, and that is best left to more specific methods. I mention these methods to highlight that there are some empty methods, and will skip the rest.
@Override
public void enterMarkdownItem(myMDToHTMLParser.MarkdownItemContext ctx) {}
@Override
public void exitMarkdownItem(myMDToHTMLParser.MarkdownItemContext ctx) {}
Headers
Headers are straightforward. We count the
#
symbols before the text, and use that count to set the header tags to the correct value. After exiting, the header count is reset to allow for later headers.
@Override
public void enterHeader(myMDToHTMLParser.HeaderContext ctx) {
for (org.antlr.v4.runtime.tree.ParseTree c : ctx.children) {
if (Objects.equals(c.getText(), "#")) {
currentHeaderCount++;
} else {
break;
}
}
this.OutString
.append("<h")
.append(currentHeaderCount)
.append(">\n");
}
@Override
public void exitHeader(myMDToHTMLParser.HeaderContext ctx) {
this.OutString
.append("\n</h")
.append(currentHeaderCount)
.append(">\n");
currentHeaderCount = 0;
}
Code blocks
Now for code tags. In the pervious version, the function to add code tags was about 60–70 lines long, as it combined the logic for identifying the structure of the tokens with adding the tags.
@Override
public void enterMultilineCodeBlock(myMDToHTMLParser.MultilineCodeBlockContext ctx) {
this.OutString
.append("<pre>\n")
.append("<code>\n");
}
@Override
public void exitMultilineCodeBlock(myMDToHTMLParser.MultilineCodeBlockContext ctx) {
this.OutString
.append("</code>\n")
.append("</pre>\n");
}
@Override
public void enterInlineCodeBlock(myMDToHTMLParser.InlineCodeBlockContext ctx) {
this.OutString.append("<code>\n");
}
@Override
public void exitInlineCodeBlock(myMDToHTMLParser.InlineCodeBlockContext ctx) {
this.OutString.append("</code>\n");
}
@Override
public void enterCodeBlockLine(myMDToHTMLParser.CodeBlockLineContext ctx) {
}
@Override
public void exitCodeBlockLine(myMDToHTMLParser.CodeBlockLineContext ctx) {
this.OutString.append("\n");
}
Thankfully, with the separation of the lexer and the parser, the code to add HTML tags is very simple. One feature, which has not been added yet, is the ability to ignore series of backquotes within a code block. On some occasions, I want to display the plain text of a code block within another code block. For now, these have to be removed and added back into the HTML later on.
Italicised and Emboldened Text
Bold and italics functions are not much more complicated. When entering, if an end footnote is being added then the current tags are appended to the
currentEndNoteString
string. Otherwise, add to the
OutString
. All asterisks and internal text are accounted for by other methods.
@Override
public void enterItalicsAndBold(myMDToHTMLParser.ItalicsAndBoldContext ctx) {
if (addingEndNotes) {
this.currentEndNoteString.append("<i>\n<b>\n");
} else {
this.OutString.append("<i>\n<b>\n");
}
}
@Override
public void exitItalicsAndBold(myMDToHTMLParser.ItalicsAndBoldContext ctx) {
if (addingEndNotes) {
this.currentEndNoteString.append("</b>\n</i>\n");
} else {
this.OutString.append("</b>\n</i>\n");
}
}
The separate bold and italics methods are effectively the same as the above.
Footnotes
There are two parts to the footnote logic: renumbering the inline footnotes so that they are numbered from 1 and up, and reordering the footnotes at the end.
A blog post file can have footnotes in the following order:
Throwaway line
This[^4] paragraph references a footnote.[^3]
This paragraph[^1] also has[^2] a footnote.
[^1]: This is the reference.
[^2]: This is a footnote.
[^3]: Surprise!
[^4]: Fourth note.
Which needs to be rearranged into:
<html>
<head>
<meta charset=\"UTF–8\"/>
</head>
<body>
Throwaway line
</p>
<p>
This
<a id=\"footnote–anchor–1\" href=\"#footnote–1\">
[1]
</a>
paragraph references a footnote.
<a id=\"footnote–anchor–2\" href=\"#footnote–2\">
[2]
</a>
</p>
<p>
This paragraph
<a id=\"footnote–anchor–3\" href=\"#footnote–3\">
[3]
</a>
also has
<a id=\"footnote–anchor–4\" href=\"#footnote–4\">
[4]
</a>
a footnote.
</p>
<p>
<p id=\"footnote–1\">
<a href=\"#footnote–anchor–1\">
[1]
</a>
Fourth note.
</p>
<p id=\"footnote–2\">
<a href=\"#footnote–anchor–2\">
[2]
</a>
Surprise!
</p>
<p id=\"footnote–3\">
<a href=\"#footnote–anchor–3\">
[3]
</a>
This is the reference.
</p>
<p id=\"footnote–4\">
<a href=\"#footnote–anchor–4\">
[4]
</a>
This is a footnote.
</p>
</p>
</body>
</html>
A little logic solves this:
@Override
public void enterEndOfFileFootnote(myMDToHTMLParser.EndOfFileFootnoteContext ctx) {
if (!addingEndNotes) {
addingEndNotes = true;
}
}
@Override
public void exitEndOfFileFootnote(myMDToHTMLParser.EndOfFileFootnoteContext ctx) {
this.endNotes.put(
this.footnoteMap.get(Integer.valueOf(ctx.NUMBER().toString())),
this.currentEndNoteString.toString()
);
this.currentEndNoteString.setLength(0);
}
@Override
public void enterInlineFootnote(myMDToHTMLParser.InlineFootnoteContext ctx) {}
@Override
public void exitInlineFootnote(myMDToHTMLParser.InlineFootnoteContext ctx) {
footnoteMap.put(
Integer.valueOf(ctx.NUMBER().toString()),
currentInlineFootnoteNumber
);
this.OutString
.append("<a id=\"footnote–anchor–")
.append(currentInlineFootnoteNumber)
.append("\" href=\"#footnote–")
.append(currentInlineFootnoteNumber)
.append("\">[")
.append(currentInlineFootnoteNumber)
.append("]</a>\n");
currentInlineFootnoteNumber++;
}
For the inline footnotes, we store the value of the current footnote number against the
currentInlineFootnoteNumber
value. Then, the current value of the
currentInlineFootnoteNumber
is used for the HTML text.
Upon finding the first end note, we set
addingEndNotes
to true. As seen earlier, if a node could be adding text to a foot note sentence, it will check if it should. I assume that there is no text after the end notes, and therefore there is no need to change the variable back to false.
When exiting an end note node, we store the
currentEndNoteString
in a hash map for later reference rather than adding it here. Afterwards, the buffer is empty by setting its length to 0.[12]
Images
Images are essentially added as–is. We prepend the path to the image directory, using the default from earlier if it none as has been provided.
@Override
public void enterImage(myMDToHTMLParser.ImageContext ctx) {
}
@Override
public void exitImage(myMDToHTMLParser.ImageContext ctx) {
this.OutString
.append("<figure class=\"image\">\n")
.append("<img src=\"")
.append(imagePath)
.append(ctx.imageName().getText())
.append("\">\n")
.append("</figure>\n");
}
Unordered Lists
Unordered list tags are also surprisingly simple to add as well. After adding the surrounding tags, all the text for each list item is added by other methods further down the parse tree.
@Override
public void enterList(myMDToHTMLParser.ListContext ctx) {
this.OutString.append("\n<ul>\n");
}
@Override
public void exitList(myMDToHTMLParser.ListContext ctx) {
this.OutString.append("</ul>\n");
}
@Override
public void enterListLine(myMDToHTMLParser.ListLineContext ctx) {
this.OutString.append("<li>\n");
}
@Override
public void exitListLine(myMDToHTMLParser.ListLineContext ctx) {
this.OutString.append("</li>\n");
}
Tables
Tables are much the same. Despite the relatively large number of methods, all they do is add opening and closing tags.
@Override
public void enterTable(myMDToHTMLParser.TableContext ctx) {
this.OutString.append("<table class=\"table is–hoverable\">\n");
}
@Override
public void exitTable(myMDToHTMLParser.TableContext ctx) {
this.OutString.append("</tbody>\n").append("</table>\n");
}
@Override
public void enterTableHeader(myMDToHTMLParser.TableHeaderContext ctx) {
this.OutString.append("<thead>\n").append("<tr>\n");
}
@Override
public void exitTableHeader(myMDToHTMLParser.TableHeaderContext ctx) {
this.OutString.append("</tr>\n").append("</thead>\n");
}
@Override
public void enterTableBorder(myMDToHTMLParser.TableBorderContext ctx) {}
@Override
public void exitTableBorder(myMDToHTMLParser.TableBorderContext ctx) {
this.OutString.append("<tbody>\n");
}
@Override
public void enterTableBodyRow(myMDToHTMLParser.TableBodyRowContext ctx) {
this.OutString.append("<tr>\n");
}
@Override
public void exitTableBodyRow(myMDToHTMLParser.TableBodyRowContext ctx) {
this.OutString.append("</tr>\n");
}
@Override
public void enterTableHeaderCell(myMDToHTMLParser.TableHeaderCellContext ctx) {
this.OutString.append("<th>\n");
}
@Override
public void exitTableHeaderCell(myMDToHTMLParser.TableHeaderCellContext ctx) {
this.OutString.append("</th>\n");
}
@Override
public void enterTableCell(myMDToHTMLParser.TableCellContext ctx) {
this.OutString.append("<td>\n");
}
@Override
public void exitTableCell(myMDToHTMLParser.TableCellContext ctx) {
this.OutString.append("</td>\n");
}
Single Token Rules
The parser rules for individual tokens are also quite 'dumb'. Aside from
pound
and
exclamationMark
which can appear in foot note sentences, all they do is add the token as–is.
@Override
public void enterPound(myMDToHTMLParser.PoundContext ctx) {}
@Override
public void exitPound(myMDToHTMLParser.PoundContext ctx) {
if (addingEndNotes) {
this.currentEndNoteString.append("#");
} else {
this.OutString.append("#");
}
}
@Override
public void enterVerticalLine(myMDToHTMLParser.VerticalLineContext ctx) {}
@Override
public void exitVerticalLine(myMDToHTMLParser.VerticalLineContext ctx) {
this.OutString.append(htmlEntityMap.get("|"));
}
@Override
public void enterAsterisk(myMDToHTMLParser.AsteriskContext ctx) {}
@Override
public void exitAsterisk(myMDToHTMLParser.AsteriskContext ctx) {
this.OutString.append("*");
}
@Override
public void enterDash(myMDToHTMLParser.DashContext ctx) {}
@Override
public void exitDash(myMDToHTMLParser.DashContext ctx) {
if (addingEndNotes) {
this.currentEndNoteString.append("–");
} else if (addingTextBetweenAnchorBrackets) {
textBetweenAnchorBrackets.append(htmlEntityMap.get("–"));
} else {
this.OutString.append(htmlEntityMap.get("–"));
}
}
@Override
public void enterBackquote(myMDToHTMLParser.BackquoteContext ctx) {}
@Override
public void exitBackquote(myMDToHTMLParser.BackquoteContext ctx) {
this.OutString.append("`");
}
@Override
public void enterCarat(myMDToHTMLParser.CaratContext ctx) {}
@Override
public void exitCarat(myMDToHTMLParser.CaratContext ctx) {
this.OutString.append("^");
}
@Override
public void enterExclamationMark(myMDToHTMLParser.ExclamationMarkContext ctx) {}
@Override
public void exitExclamationMark(myMDToHTMLParser.ExclamationMarkContext ctx) {
if (addingEndNotes) {
this.currentEndNoteString.append("!");
} else if (addingTextBetweenAnchorBrackets) {
textBetweenAnchorBrackets.append("!");
} else {
this.OutString.append("!");
}
}
Links
Links require reordering a bit of text. Upon entering the start of a link, I capture the text the user is supposed to be able to read in a separate variable (the mechanics of this are shown below in
default
). Upon exiting, I return to adding the default tokens as–is to the
OutString
. Once exiting from there, the captured text is appended to the
OutString
and a losing anchor tag is added.
@Override
public void enterLink(myMDToHTMLParser.LinkContext ctx) {}
@Override
public void exitLink(myMDToHTMLParser.LinkContext ctx) {}
@Override
public void enterLinkStart(myMDToHTMLParser.LinkStartContext ctx) {
this.addingTextBetweenAnchorBrackets = true;
}
@Override
public void exitLinkStart(myMDToHTMLParser.LinkStartContext ctx) {
this.addingTextBetweenAnchorBrackets = false;
}
@Override
public void enterLinkEnd(myMDToHTMLParser.LinkEndContext ctx) {
this.OutString.append("<a href=\"");
}
@Override
public void exitLinkEnd(myMDToHTMLParser.LinkEndContext ctx) {
this.OutString
.append("\">")
.append(this.textBetweenAnchorBrackets.toString())
.append("</a>\n");
}
Default Text
Default has six options:
- either the current piece of text should be replaced with an HTML entity or not,
-
either it should be appended to the main
OutString,currentEndNoteString, ortextBetweenAnchorBrackets.
@Override
public void enterDefault(myMDToHTMLParser.DefaultContext ctx) {}
@Override
public void exitDefault(myMDToHTMLParser.DefaultContext ctx) {
if (htmlEntityMap.containsKey(ctx.getText())) {
if (addingEndNotes) {
this.currentEndNoteString.append(htmlEntityMap.get(ctx.getText()));
} else if (addingTextBetweenAnchorBrackets) {
textBetweenAnchorBrackets.append(htmlEntityMap.get(ctx.getText()));
} else {
this.OutString.append(htmlEntityMap.get(ctx.getText()));
}
} else {
if (addingEndNotes) {
this.currentEndNoteString.append(ctx.getText());
} else if (addingTextBetweenAnchorBrackets) {
textBetweenAnchorBrackets.append(ctx.getText());
} else {
this.OutString.append(ctx.getText());
}
}
}
And that is it. Compare to the previous outing, the amount of logic code required to transpile the incoming text is small. With the identification and HTML–creating logic being separated, much less code needs to be written here with most of the HTML logic can be devolved to other methods. At points where issues with the grammar were noticed, all that had to be done was to paste the input into the ANTLR plugin's preview, update the grammar, check some other inputs in case they had broken, regenerate the ANTLR files, update the Listener, and re–run the tests.
Speaking of tests.
HtmlMdListenerTest
I ported over the tests cases from my previous outing to here. These provide integration tests against
AntlrParser.transpileMDToHTML()
, and are all run with JUnit.
New line characters between HTML tags are removed. This is to avoid an additional newline character between tags from causing the tests to fail, when the existence of a new line character there provides no semantic difference for HTML – browsers will render it the same way regardless. This does come with a trade–off of making the test output harder to read, however, and I have toyed with the idea of switching it back.
The majority of tests are added as–is. There are a couple of changes. Tables are not tested separately as a header, border, and body, but instead as a single unit. All tests also end with a
\n
, as this is required for the
sentence
parser rule to recognise the text structure correctly.
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class AntlrParserTest {
String htmlStart = "<html><head><meta charset=\"UTF–8\"/></head><body><div class=\"content\"><p>";
String htmlEnd = "</p></div></body></html>";
String removeNewLineChars (String strIn) {
return strIn.replaceAll(">\n", ">").replaceAll("\n<", "<");
}
@Test
void transpileMDToHTML() {
assertEquals(
"",
removeNewLineChars(AntlrParser.transpileMDToHTML(
"", ""
)
)
);
assertEquals(
htmlStart +
"This is a plain text file." +
htmlEnd,
removeNewLineChars(AntlrParser.transpileMDToHTML(
"This is a plain text file.\n", ""
)
)
);
//...
}
After some back–and–forth, resulting in the grammar present above, all tests pass. This includes the small text file test – a string of text containing a variety of rules – used last time. Note that the backquotes were added into the code block below after transpiling.
# Introduction
## A Small File
This is a *small* file. It contains – neigh – requires the program to correctly translate a variety of different Obsidian Markdown elements into the HTML elements I want.
![[image_name.png]]
For example:
– paragraphs[^1]
– \"0 < 1\"\n– \"2 > 1\"
– **and**
– ***headings***
– `Code blocks`
```Pseudocode
fn removeCharacterFromList(remList list, charToRemove char) list {
match remList {
case x::[]:
match x {
charToRemove: []
_: x
}
case x::xs:
match x {
charToRemove: removeCharacterFromList(xs, charToRemove)
_: x::removeCharacterFromList(xs, charToRemove)
}
}
}
removeCharacterFromList(['a', 'b', 'c'], 'a')
```
## A table conclusion
Another footnote.[^2]
| A table | must have | columns |
|––|––|––|
| and rows. | which may have an arbitrary amount of content | |
[^1]: With footnotes!
[^2]: Pseudocode.
<html>
<head>
<meta charset=\"UTF–8\"/>
</head>
<body>
<p>
<h1>
Introduction
</h1>
</p>
<p>
<h2>
A Small File
</h2>
</p>
<p>
This is a
<i>
small
</i>
file. It contains – neigh – requires the program to correctly translate a variety of different Obsidian Markdown elements into the HTML elements I want.
</p>
<p>
<figure class=\"image\">
<img src=\"/directory_name/image_name.png\">
</figure>
</p>
<p>
For example:
</p>
<p>
<ul>
<li>
paragraphs
<a id=\"footnote–anchor–1\" href=\"#footnote–1\">
[1]
</a>
</li>
<li>
"0 < 1"
</li>
<li>
"2 > 1"
</li>
<li>
<b>
and
</b>
</li>
<li>
<i>
<b>
headings
</b>
</i>
</li>
<li>
<code>
Code blocks
</code>
</li>
</ul>
</p>
<p>
<pre>
<code>
fn removeCharacterFromList(remList list, charToRemove char) list {
match remList {
case x::[]:
match x {
charToRemove: []
_: x
}
case x::xs:
match x {
charToRemove: removeCharacterFromList(xs, charToRemove)
_: x::removeCharacterFromList(xs, charToRemove)
}
}
removeCharacterFromList(['a', 'b', 'c'], 'a')
</code>
</pre>
</p>
<p>
<h2>
A table conclusion
</h2>
</p>
<p>
Another footnote.
<a id=\"footnote–anchor–2\" href=\"#footnote–2\">
[2]
</a>
</p>
<p>
<table class=\"table is–hoverable\">
<thead>
<tr>
<th>
A table
</th>
<th>
must have
</th>
<th>
columns
</th>
</tr>
</thead>
<tbody>
<tr>
<td>
and rows.
</td>
<td>
which may have an arbitrary amount of content
</td>
<td>
</td>
</tr>
</tbody>
</table>
</p>
<p>
<p id=\"footnote–1\">
<a href=\"#footnote–anchor–1\">
[1]
</a>
With footnotes!
</p>
<p id=\"footnote–2\">
<a href=\"#footnote–anchor–2\">
[2]
</a>
Pseudocode.
</p>
</p>
</body>
</html>
Conclusion
Developing a transpiler with ANTLR was very quick and allowed for a lot of iterative development. There is little comparison between the ease of writing a transpiler with ANTLR compared to writing one by hand, particularly when rules needed to be corrected.
If you would like to try ANTLR, check out the official webpage[13] , Terence Parr's YouTube channel[14] , and Tomasetti's various tutorials.[15] There are a number of grammars available online if you would like to see what others have developed already.[16]
Code
All code is available on GitHub:
References
[1] Christian Marc Joubert, 'A Test-Driven Approach to Translating a Markdown Document into HTML', https://acrossthegrove.blue/3
[2] Terence Parr, ‘ANTLR’, 2024, https://www.antlr.org/.
[3] Gabriele Tomassetti, ‘The ANTLR Mega Tutorial’, 2024, https://tomassetti.me/antlr-mega-tutorial/.
[4] Terence Parr, ‘Mini-Markdown: MarkdownParser.G4’, c 2014, https://github.com/parrt/mini-markdown/blob/master/src/org/antlr/md/MarkdownParser.g4.
[5] Terence Parr, ‘ANTLR v4 Plugin’, 1 February 2023, https://plugins.jetbrains.com/plugin/7358-antlr-v4.
[6] Gabriele Tomassetti, ‘The ANTLR Mega Tutorial: 6. Lexers and Parsers’, 2024, https://tomassetti.me/antlr-mega-tutorial/#chapter23.
[7] Ibid.
[8] Ibid.
[9] Terence Parr, ‘Download ANTLR’, 2024, https://www.antlr.org/download.html. Click on the 'Complete ANTLR 4.13.1' Java binaries jar link under 'ANTLR tool and Java Target'.
[10] Michael Mina, ‘How to Install Antlr4?’, accessed 14 February 2020, https://stackoverflow.com/questions/41021963/how-to-install-antlr4.
[11] Footnotes may be added out of order. Whilst the footnotes at the end are all numbered correctly.
[12] waterfallrain, ‘Clearing a String Buffer/Builder after Loop’, accessed 19 February 2024, https://stackoverflow.com/questions/2242471/clearing-a-string-buffer-builder-after-loop.
[13] https://www.antlr.org/index.html
[14] Terence Parr, ‘YouTube: Professor Parr: Playlists’, 2024, https://www.youtube.com/@professorparr7301/playlists.
[15] Gabriele Tomassetti, ‘Articles’, 2024, https://tomassetti.me/.
[16] antlr, ‘Grammars-V4’, 2024, https://github.com/antlr/grammars-v4.